【検証#02】Lorentzian Classification (ローレンツ分類)¶
この記事の3行まとめ
- TradingViewで大流行した機械学習手法「Lorentzian Classification」をMQL5で再実装。
- ユークリッド距離ではなくローレンツ距離を使うことで、外れ値(ノイズ)の影響を劇的に低減。
- RSI, CCI, ADXなどの多次元特徴量から「似た相場」を過去から探し出し、未来を多数決で予測(k-NN)。
Lorentzian Classification とは?¶
TradingViewで公開され、その高いパフォーマンスから世界中で話題になったインジケータ「Machine Learning: Lorentzian Classification」。 この手法の核となるアイデアは、「相場の類似性」を測る定規を変えることにあります。
なぜ「ローレンツ距離」なのか?¶
通常、データ間の「近さ」を測るにはユークリッド距離(ピタゴラスの定理でおなじみの直線距離)が使われます。しかし、金融市場のデータにはスパイク(急激な価格変動)やノイズが頻繁に含まれます。
ユークリッド距離は、数値の差を二乗するため、極端な値(外れ値)の影響を強く受けすぎてしまいます。つまり、たった一度のショック相場のせいで、「似ていない」と判定されてしまうことがあるのです。
そこで登場するのがローレンツ距離 (Lorentzian Distance) です。
この数式の特徴は、対数(\(\ln\)) を使っている点です。差が大きくなっても距離スコアが爆発的に増えないため、「外れ値に対してロバスト(頑健)」 という性質を持ちます。これにより、ノイズを無視して本質的なチャート形状の類似性を捉えることができます。
実装ロジック (k-NN)¶
この手法の中身は、機械学習の古典的なアルゴリズムである k-近傍法 (k-Nearest Neighbors, k-NN) です。
- 特徴量抽出: 現在の足の RSI, CCI, ADX などの値をベクトル化します。
- 過去探索: 過去2000本(設定値)のバーを振り返り、現在と「形が似ている」場面を探します。ここでローレンツ距離を使います。
- 近傍選択: 距離が近い上位 \(k\) 個(デフォルト8個)の過去データを選び出します。
- 未来予測: 選ばれた過去データの「その後の値動き」を集計し、多数決で上がりそうか下がりそうかを判定します。
MQL5コード¶
以下のコードは、このロジックをMQL5のインジケータとして実装したものです。 計算負荷を抑えるため、探索範囲(Training Data Size)はデフォルトで2000本に制限していますが、現代のPCであれば十分高速に動作します。
Column_Lorentzian_Class.mq5 (v1.01) をダウンロード
ソースコードの一部を表示
// ローレンツ距離の計算関数
double CalculateLorentzianDistance(const FeatureVector &v1, const FeatureVector &v2)
{
double dist = 0.0;
// 各特徴量の差の絶対値に対数を適用して合算
dist += MathLog(1.0 + MathAbs(v1.rsi - v2.rsi));
dist += MathLog(1.0 + MathAbs(v1.cci - v2.cci));
dist += MathLog(1.0 + MathAbs(v1.adx - v2.adx));
dist += MathLog(1.0 + MathAbs(v1.dmi_plus - v2.dmi_plus));
dist += MathLog(1.0 + MathAbs(v1.dmi_minus - v2.dmi_minus));
return dist;
}
v1.01 アップデート: ダマシの除去¶
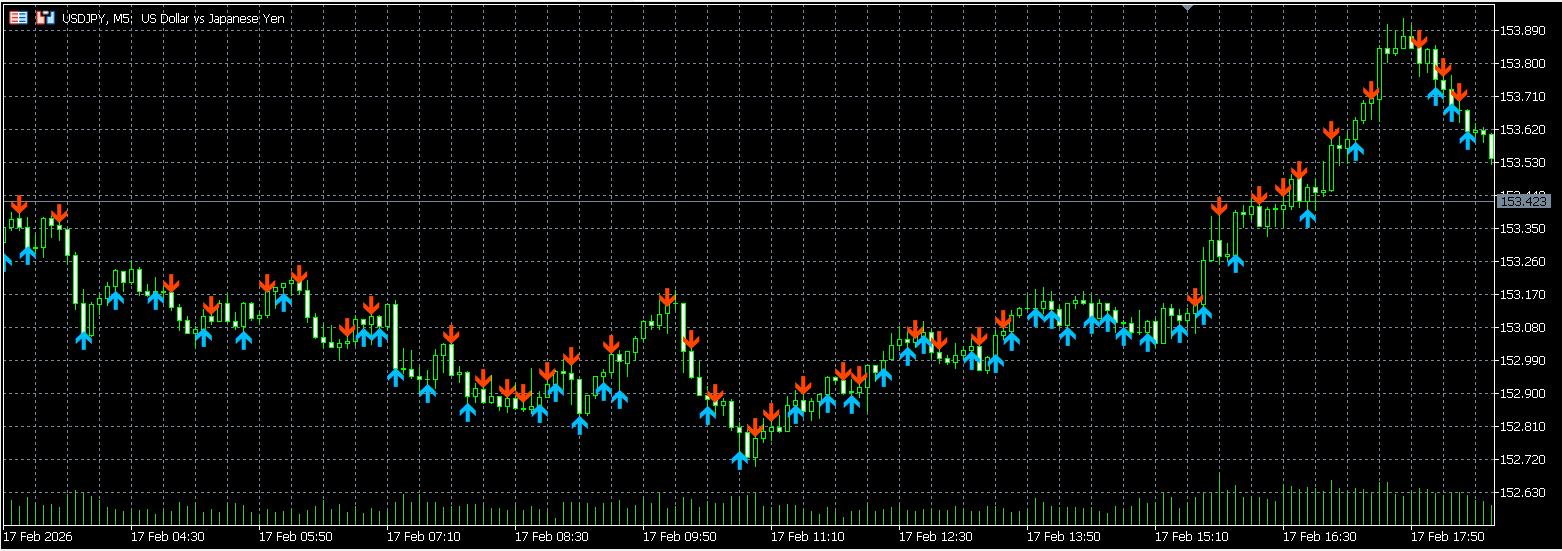
初期バージョンでは「少しでも票が多ければ矢印を出す」仕様だったため、レンジ相場で矢印が乱発する問題がありました。 v1.01では、より実用的なトレード判断ができるよう、以下のフィルタリング機能を追加しました。
新パラメータの設定¶
| パラメータ | デフォルト | 説明 |
|---|---|---|
MinVotes | 5 | 近傍8個のうち、5個以上が同方向でないと矢印を出さない(閾値判定)。 値を増やすほど「確度の高い」シグナルのみが表示されます。 |
FilterConsecutive | true | 連続して同じ方向の矢印が出た場合、2回目以降を非表示にします。 これにより、矢印は「トレンドの発生・転換点」のみに表示され、チャートが見やすくなります。 |
トレンドとレンジの見方¶
このインジケータを使って、どのように相場環境を判断すればよいかの指針です。
1. トレンドの初動を捉える¶
FilterConsecutive = true の設定では、「無風状態(矢印なし)から、ポツンと矢印が出た瞬間」 がトレンド発生のサインです。 k-NNが「過去の似たパターンでは、この後大きく動いた」と判断したポイントですので、ここでの順張りエントリーが基本戦略となります。
2. レンジ相場の判断¶
MinVotes の条件(デフォルト: 8票中5票以上)を満たさない場合、矢印は表示されません。 つまり、「矢印が出ていない期間」=「相場の方向感が定まっていないレンジ期間」 と判断できます。 無理にエントリーせず、次の明確な矢印(合意形成)が出るまで待つのが賢明です。
3. ダマシへの対処¶
それでも逆行することはあります。その場合、「逆方向の矢印」が出たら即座にドテン(または損切り) するのが有効です。 機械学習が「やっぱりこっちだ」と意見を変えたことを意味するため、素直に従う方が大怪我を防げます。
検証と考察¶
メリット¶
- レンジ相場に強い: 過去の類似パターンを探すため、サイクル性のあるレンジ相場では驚異的な勝率を発揮することがあります。
- 適応力: 固定のロジックではなく、直近のデータセット(過去2000本)に基づいて判断するため、相場環境の変化にある程度追従します。
デメリット・注意点¶
- 計算コスト: 毎ティック(または足確定ごと)に過去データの全探索を行うため、EA化してバックテストを行うと非常に重くなります。
- リペイント(に見える現象): k-NNは「現在の確定した足」までのデータを使えば、過去のシグナルはリペイントしません。しかし、パラメータ(探索期間など)を変えると過去の分類結果も全て変わるため、カーブフィッティングにならないよう注意が必要です。
次のステップ¶
このローレンツ分類をEAに組み込む場合、「計算の軽量化」 が最大の課題になります。毎回再計算するのではなく、トレーニング(近傍探索)を数時間に1回にする、あるいは距離計算を近似するなどの工夫が必要になるでしょう。
関連記事¶
この記事を読んだ方におすすめ
- 🌀 【検証#01】ハースト指数 — カオス理論で市場の「記憶」を読む — 別の数学的アプローチで相場の性質を判定
- 🔮 【検証#03】隠れマルコフモデル (HMM) — 確率モデルで相場の「状態」を推定
- 🏯 トレンド相場 vs レンジ相場:江戸の米相場に学ぶ — 相場判定の歴史と限界
- 🤖 【実験#03】マーチンゲールEAの全仕様を公開 — フィルターを活用したEA実装例